情報処理学会 第83回全国大会
2021年情報処理学会全国大会
今年も参加しました
情報処理学会第83回全国大会
オンライン開催のため,以前のように現地の写真をレポートすることができないのが残念です.
2017年情報処理学会全国大会。 - なぜか数学者にはワイン好きが多い
情報処理学会第76回全国大会に行ってきた - なぜか数学者にはワイン好きが多い
第75回情報処理学会全国大会 - なぜか数学者にはワイン好きが多い
2012年第74回情報処理学会全国大会出席まとめ - なぜか数学者にはワイン好きが多い
情報処理学会全国大会2011 - なぜか数学者にはワイン好きが多い
第70回情報処理学会全国大会 - なぜか数学者にはワイン好きが多い
初のオンライン開催では,バタバタと決まったこともあり,学生さんの参加者が激減した記憶があります.
情報処理学会第82回全国大会
が,今回は参加者は多かったように思います.
印象的だったのは,オンラインに慣れている何人かの学生さんが,ビデオ映像を入れて上手にプレゼンテーションをアピールした発表をしていることです.Zoom操作・パソコントラブル等もずいぶん減ったような印象でした.
ちょっとだけ負担が増えたことは,情報処理学会ではオンライン開催のトラブルを防ぐため,セッションの座長の他に「座長補佐」というものを置くようになりました.だいたいの人は座長と座長補佐の両方を引き受けることになるため,準備の手間が2倍になった感じです.まあ,仕方がないかなーと思います.
また,オンラインの方が質疑応答参加のハードルが高いのか,質問等が圧倒的に減ったように思います.座長も現場の雰囲気が見えないために時間により質疑応答を打ち切りやすく,時間は比較的守られる反面,全国大会のコミュニケーションを促進するという目的に対してはイマイチのイベントになっているなあという気がしました.
ああ,本当に字ばっかりの記事になった笑
自分の発表の時に,前の職場の同僚が聴講参加しているのを見つけてしまい,超緊張した&もっと面白いネタで発表すれば良かったと後悔したのは秘密です.
# t2sy氏,君だw
Jupyter labをインストールしてScalaをSparkで使う
この間,
注:Jupyter自体は予めインストールされているとします.
と書いたところを,一応丁寧に.
自分の備忘録として.
AWS EC2にインストールする必要が出たので.
EC2にデフォルトではpython2しか入っていなかったので,python3を入れてjupyterをインストールします.
sudo yum install python3-devel pip-3 install --user jupyterlab
jupyterを立ち上げた時にブラウザが立ち上がらないようにするとかパスワードやトークンを不必要にしてセキュリティレベルを落とす(アクセス元制限とか他の方法でセキュリティ設定がされていることとする)とか,設定を変更します.
jupyter lab --generate-config emacs .jupyter/jupyter_lab_config.py c.ExtensionApp.open_browser = False c.ServerApp.token = ''
ここまででjupyter-labを立ち上げると,ランチャーにはデフォルトで登録されているpythonなどが出ます.

ここで,紹介した方法でalmondをインストールします.
Scala/SparkのJupterカーネル「Almond」の導入 - なぜか数学者にはワイン好きが多い
その後,jupyter-labを立ち上げると,ランチャーにscalaが出ます.

Scala(almond)を選んでノートブックを立ち上げたあと,sparkを使うにはライブラリをインポートします.
あと,ドキュメントにあるようにログレベルも変更します.
Spark · almond
import $ivy.`org.apache.spark::spark-sql:3.1.1` import $ivy.`sh.almond::almond-spark:0.11.0` import org.apache.log4j.{Level, Logger} Logger.getLogger("org").setLevel(Level.OFF)
ライブラリのインポートが成功したあとに,sparkセッションのインスタンスを作成します.
import org.apache.spark.sql._ val spark = { NotebookSparkSession.builder() .master("local[*]") .getOrCreate() }
あとは,sparkを使う感じで実行ができます.
import spark.implicits._ val a = Seq(1,2,3).toDF a.show +-----+ |value| +-----+ | 1| | 2| | 3| +-----+
簡単で,素敵ですね(colla風)
Scala/SparkのJupterカーネル「Almond」の導入
Jupyter Almondカーネルをインストールする
Spark/Scalaを使うことができるJupyterのカーネルとして,Apache Toreeのメンテナンスをしています.
Apache Toreeは,Spark3対応の開発が進んでいる状況ですが,なにぶん開発がアクティブとは言い難いです.
GitHub - apache/incubator-toree: Mirror of Apache Toree (Incubating)
最後のコミットは昨年8月のようです.
Prepare for next development interaction 0.6.0.dev1 · apache/incubator-toree@fb61d80 · GitHub
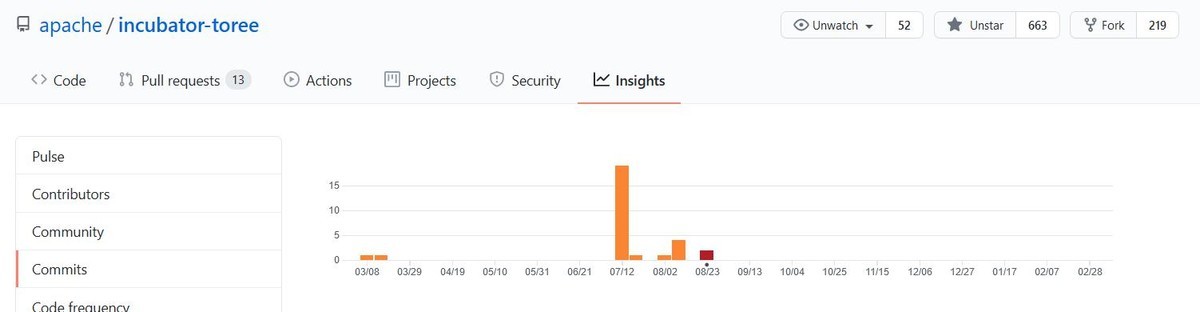
Commit Activityを見ると開発の活発度は一目瞭然です.
そこで,Almondを試しにインストールしてみました.
インストール方法
オフィシャルサイトでは,色々なインストール方法が紹介されています.
Installation · almond
私はこれで行きました.
$ curl -Lo coursier https://git.io/coursier-cli $ chmod +x coursier $ ./coursier -J-Dhttps.proxyHost=[Proxyのアドレス] -J-Dhttps.proxyPort=[Proxyのポート] bootstrap almond:0.11.0 --scala 2.12.9 -o almond $ ./almond --install --name 'Scale(almond)' --id scala_almond
注:Jupyter自体は予めインストールされているとします.
Proxy設定について
proxyが必要な環境だったので,結構ハマりました.
インストールの際は,上記の用にcoursierコマンドに,Java用のProxy設定オプションを加えます.また,Jupyterを立ち上げてカーネルとしてscala_almondを選んでからも,ライブラリインストールのために以下のコマンドをノートブック上で実行します.
System.setProperty("https.proxyHost","Proxyのアドレス") System.setProperty("https.proxyPort", "Proxyのポート")
Sparkを使うためには,以下のようにSparkのライブラリを導入します.
import $ivy.`org.apache.spark::spark-sql:3.1.1`
そういや,ちょうどSpark-3.1.1がリリースされました.
Spark 3.1.1 released | Apache Spark
AWS EMRでSpark RAPIDSを使う
AWSでSpark RAPIDSを使うには
クラウドじゃなくて,自前のサーバでSpark RAPIDSを使うには,Spark RAPIDS一式を準備する必要があります.
マシンがX86ならビルド済みのライブラリがありますが,Power PCだと自前で用意する必要があります.
Spark RAPIDSを試したら凄かった - なぜか数学者にはワイン好きが多い
とてつもなく苦労して,作業時間は2週間かかりました.
しかし,クラウドだと,苦労しません...
The current EMR 6.2.0 release supports Spark version 3.0.1 and RAPIDS Accelerator version 0.2.0. For more details of supported applications, please see the EMR release notes.
EMR6.2ではSpark3.0.1及びRAPIDS Accelarator0.2.0をサポートしています.
Using the Nvidia Spark-RAPIDS Accelerator for Spark - Amazon EMR
With Amazon EMR release version 6.2.0 and later, you can use Nvidia’s RAPIDS Accelerator for Apache Spark plugin to accelerate Spark using EC2 graphics processing unit (GPU) instance types.
EMR6.2以上では,Sparkを高速化するためにEC2 GPUインスタンスを使うNVIDIAのRAPIDS Accelarator Sparkプラグインを使うことができます.
AWSのEMR 6.2(2021/02/09時点の最新バージョン)では,追加のライブラリ等は無しに,設定するだけでSpark RAPIDSを使うことができます.基本的には,設定はこれだけ.
{ "Classification":"spark", "Properties":{ "enableSparkRapids":"true" } }
実際にはまだ設定はありますが,依存するjarなどの書き並べるような設定は必要なく,EMR側で準備されているところがポイントです.
当然,コアインスタンスにはGPUを積んでいるインスタンスが必要で,現時点の東京リージョンでは,こちらが一番安いインスタンスです.
| インスタンスサイズ | vCPU | メモリ (GB) | GPU | ストレージ (GB) | オンデマンド料金/時間* | |
| 単一の GPU VM | g4dn.xlarge | 4 | 16 | 1 | 125 | 0.526 USD |
AWSのページによって料金に違いがあるのですが,$0.5--$0.7のようです.EMRのデフォルトのm5.xlargeが$0.124程度のため5倍くらい値段が高いです.
EMR6.2で利用できるSparkはSpark3であり,Spark3はScala2.12を使う必要があります.Scala 2.11ベースのSparkを使っている場合は,バージョンアップを考えると良いと思います.
Spark3からはHadoop 3対応やAccelerator-aware Scheduler,Adaptive Query Execution,Dynamic Partition Pruning など大量の改良点があるので,効率化・高速化が期待できるということで,ぜひバージョンアップを試みると良いのではないでしょうか.
ScalaでSparkのプログラムを作る作業を高速化する.
SparkのScalaプロジェクトのビルドを爆速にする
Scalaを気に入っています.Javaはとにかくコードが冗長になり,気持ち悪かったです.Cはシンプルだし大好きです.なのでObjective-CやC++はそれなりに好きだったのですが,Cのコードがそのまま書けてしまうのは流石に今どきだとどうかと思ったり,型についてアバウト過ぎるのでデバグが大変だったりしました.Rubyは大好きでラピッドプロトタイピングしたりしてアルゴリズムを検証するには最高なのですが,ライブラリ化なんかを考えると使いにくかったり.その辺り,Scalaなら便利だし楽しいし好きです.
ただしScalaは難しくて学習コストが高い.が,これは頑張ればいい話なのでScalaのせいじゃないです.しかし,Scalaで作っているプログラムがデカくなってくると,ビルドに時間がかかる.これは努力じゃどうにもならなくて,生産性や効率を考えるととても問題です.しかし解決策はたくさんあります.
ScalaでSparkのプログラムを書くことを考えます.Scalaは各種のライブラリを色々使って便利にコーディングできるので,大量のライブラリをリンクすることになります.そして,Sparkを使う時は,sbt-assemblyなどでuber-jar/fat-jarを作るのが普通で,全てのライブラリをリンクするので時間がかかるしjarのサイズがデカくなる.
私のdeeplearning4jを使ったプログラムは,jarのサイズはこんな感じです.
-rw-r--r-- 1 tullio docker 799M Feb 6 15:37 DeepZip-assembly-0.1.0-SNAPSHOT.jar
799Mバイト.デカイよ.1Gバイトにもなろうとするファイルを作らないとならないとは.sbt-assemblyでビルドしてuber-jarを作ると,これくらい時間がかかります.
sbt:DeepZipTest> assembly [info] Strategy 'deduplicate' was applied to 3 files (Run the task at debug level to see details) [info] Strategy 'discard' was applied to 11 files (Run the task at debug level to see details) [info] Strategy 'filterDistinctLines' was applied to 14 files (Run the task at debug level to see details) [info] Strategy 'first' was applied to 2672 files (Run the task at debug level to see details) [info] Strategy 'last' was applied to 14 files (Run the task at debug level to see details) [success] Total time: 169 s (02:49), completed Feb 6, 2021 3:37:58 PM
cleanしてassemblyすると,こんな感じ.
sbt:DeepZipTest> clean [success] Total time: 11 s, completed Feb 6, 2021 3:59:37 PM sbt:DeepZipTest> assembly [info] Updating [info] Strategy 'deduplicate' was applied to 3 files (Run the task at debug level to see details) [info] Strategy 'discard' was applied to 11 files (Run the task at debug level to see details) [info] Strategy 'filterDistinctLines' was applied to 14 files (Run the task at debug level to see details) [info] Strategy 'first' was applied to 2672 files (Run the task at debug level to see details) [info] Strategy 'last' was applied to 14 files (Run the task at debug level to see details) [info] Strategy 'rename' was applied to 102 files (Run the task at debug level to see details) [success] Total time: 263 s (04:23), completed Feb 6, 2021 4:04:04 PM
3分から5分かかるんですが,長いです.タイプミスして一文字間違えただけでビルドし直し3分.イラつくだけじゃなく,本当に効率が落ちます.作業が遅くなる.
これを高速化する方法はたくさんあるのですが,単純に全てのリンクを止めるというのが簡単で効果的です.
そのマジックは,sbt-assemblyに仕込まれています.
GitHub - sbt/sbt-assembly: Deploy fat JARs. Restart processes. (port of codahale/assembly-sbt)
Splitting your project and deps JARs
To make a JAR file containing only the external dependencies, type
> assemblyPackageDependency
This is intended to be used with a JAR that only contains your project
assemblyOption in assembly := (assemblyOption in assembly).value.copy(includeScala = false, includeDependency = false)
自分のプロジェクトと依存ライブラリのjarを分離する
外部の依存ライブラリだけのJARファイルを作るには,このようにタイプして下さい:
> assemblyPackageDependency
自分のプロジェクトのファイルだけのJARファイルを作るには,このように出来ます:
assemblyOption in assembly := (assemblyOption in assembly).value.copy(includeScala = false, includeDependency = false)
使い方は簡単で,自分が作っているプロジェクト以外の依存ライブラリのjarを作っておく.
sbt:DeepZipTest> assemblyPackageDependency [info] Strategy 'deduplicate' was applied to 3 files (Run the task at debug level to see details) [info] Strategy 'discard' was applied to 11 files (Run the task at debug level to see details) [info] Strategy 'filterDistinctLines' was applied to 14 files (Run the task at debug level to see details) [info] Strategy 'first' was applied to 2672 files (Run the task at debug level to see details) [info] Strategy 'last' was applied to 14 files (Run the task at debug level to see details) [success] Total time: 178 s (02:58), completed Feb 6, 2021 4:14:04 PM ls -lh -rw-r--r-- 1 tullio docker 799M Feb 6 16:14 DeepZip-assembly-0.1.0-SNAPSHOT-deps.jar
依存ライブラリ一式のjarを作るのに3分かかってますが,これは一度作っておけばOKなので,問題ありません.jarのサイズは799Mバイトで,作りたいfat-jarの大部分を占めていることが分かります.
さて,依存ライブラリjarを作っておくと,自分で作っているコードのビルドは,ほとんど一瞬で終わります.
ビルドコマンドは,assemblyじゃなくてpackageでOK.
sbt:DeepZipTest> package [success] Total time: 0 s, completed Feb 6, 2021 4:18:25 PM ls -lh -rw-r--r-- 1 tullio docker 92K Feb 6 16:18 deepziptest_2.12-0.1.0-SNAPSHOT.jar
ビルド時間は0秒(笑),jarのファイルサイズは92Kバイト.
ビルド時間が5分だったのが0秒になります.これは効率化,向上でしょう.
Sparkで実行するには,完全なubar-jarだったら
spark-submit --class DeepZip DeepZip-assembly-0.1.0-SNAPSHOT.jar
となるところを,
spark-submit --class DeepZip --jars DeepZip-assembly-0.1.0-SNAPSHOT-deps.jar deepziptest_2.12-0.1.0-SNAPSHOT.jar
と--jarsで依存ライブラリのjarをアップロードするだけです.
ビルドが一瞬になって,Scalaの快適ライフをどうぞ!
全てのScalaプログラマーは,eed3si9n | works by eugene yokotaさんに感謝しつつsbt-assemblyを使うのが良いと思います.
Spark RAPIDSを試したら凄かった
NVIDIA Spark RAPIDSを試してみた
Apache Sparkファンとしては,Sparkの色々な活用方法を探しています.特に私はIBM PowerでSparkを使っているので,機械学習のためのライブラリを使おうとすると,色々と苦労しています.幸い,IBM Powerは,ギリギリでNVIDIAのサポートを受けています.例えば,CUDAが使えます.
ならばSparkでCUDAを使ってGPUを活用したい!
と思いますよね.
そこでSpark RAPIDS.
GitHub - NVIDIA/spark-rapids: Spark RAPIDS plugin - accelerate Apache Spark with GPUs
RAPIDSは様々なプロジェクトのトップです.
Open GPU Data Science | RAPIDS
今回は,RAPIDSの中のSpark RAPIDSだけ取り上げます.
ローカルモードで試してみる
私はIBM Power8とIBM Power9から構成されるHadoop YARNクラスタでSparkを使っています.ただ,GPUが付いているPower9は一台しか無いので,SparkをYARNモードじゃなくてlocalモードで試してみます.
細かいことはあとで説明するとして,結果を貼り付けてみます.
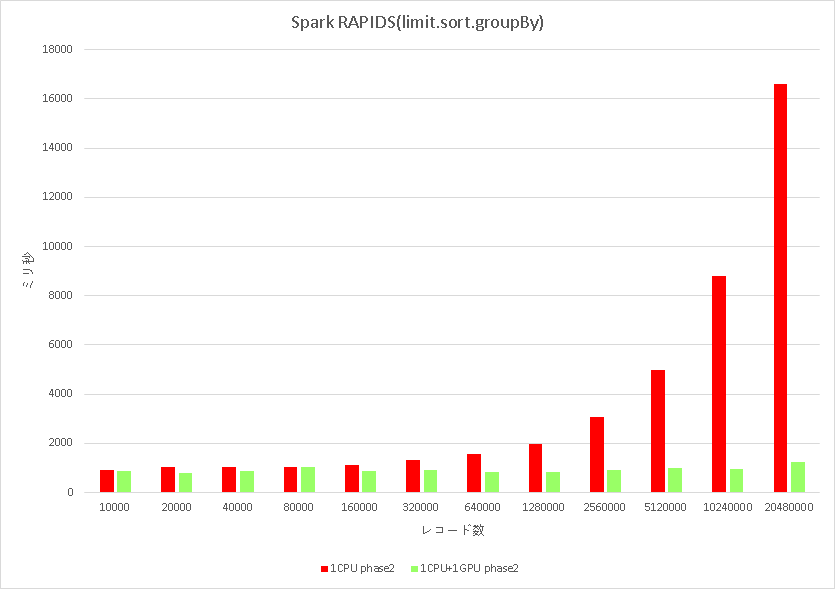
普通に,Hadoopのログファイルを読んで,limitで適当にレコード数を決めて,時間情報でsortして,あるカラムでgroupByするというSpark SQLを実行して,実行時間を計測してみました.
赤はRAPIDSを使わなかった時で,レコード数に比例して処理時間が増えています.緑はRAPIDSを使った時で,レコード数が増えても処理時間が変わりません(!).色々試した結果,GPUのメモリが溢れるまでは定数時間でイケました.
レコード数が20480000,約2000万レコードの時,sparkを--master localでCPUで実行した時は,処理時間が16秒でした.同じjarファイルをspark-submitした場合,1秒でした.16倍の高速化です.
CPUで実行する時と,GPUを使う時は,Sparkのconfigureで切り替えています.GPUを使う場合のConfはこんな感じ.
spark.rapids.shuffle.transport.enabled true spark.rapids.sql.enabled true spark.rapids.sql.explain ALL spark.rapids.sql.concurrentGpuTasks 1 spark.plugins com.nvidia.spark.SQLPlugin spark.rapids.sql.castStringToTimestamp.enabled true
詳細は,順次,報告します!
ScalaTestのDeeplearning4jのテストを簡単にしたい
Deeplearning4jのNDArray同士をアバウトに比較したい
scala> import org.nd4j.linalg.factory.Nd4j import org.nd4j.linalg.factory.Nd4j scala> val a = Nd4j.create(Array(1.0, 2.0)) a: org.nd4j.linalg.api.ndarray.INDArray = [ 1.0000, 2.0000] scala> val b = Nd4j.create(Array(1.1, 1.9)) b: org.nd4j.linalg.api.ndarray.INDArray = [ 1.1000, 1.9000] scala> a == b res0: Boolean = false
当然数値で比較するとfalseなわけですが,これをちょっとくらいの誤差だったらtrueでイコールとみなすようなことをしたいです.
Scalacticを使う
まさのそのためのライブラリがあります.
The Scalactic library is focused on constructs related to quality that are useful in both production code and tests. Although ScalaTest is tightly integrated with Scalactic, you can use Scalactic with any Scala project and any test framework. The Scalactic library has no dependencies other than Scala itself.
Scalaticライブラリは高品質なコードのためのもので,プロダクションコードとテストの両方にとって有益です.ScalaTestはScalaticと統合されているので,Scalaのプロジェクトとあらゆるテストフレームワークにおいて利用することができます.ScalaticライブラリはScala自身以外への依存はありません.
Tolerance
まず,Tolerance(耐性,許容)を使って数値をアバウトに比較できるようにします.
[ 1.0000, 2.0000]と[ 1.1000, 1.9000]が等しくなるようにしたい.まずは1.0と1.1が等しかったり,2.0と1.9が等しかったりするようにします.
scala> import org.scalactic._ import org.scalactic._ scala> import TripleEquals._ import TripleEquals._ scala> import Tolerance._ import Tolerance._ scala> val a = 1.0 a: Double = 1.0 scala> val b = 2.0 b: Double = 2.0 scala> a === 1.1 +- 0.1 res3: Boolean = true scala> b === 1.9 +- 0.1 res4: Boolean = true
なんと簡単.===じゃないとダメです.==ならこうなります.
scala> a == 1.1 +- 0.1 <console>:23: warning: comparing values of types Double and org.scalactic.TripleEqualsSupport.Spread[Double] using `==' will always yield false a == 1.1 +- 0.1 ^
型が違うので等しいとは判断されないということです.
この辺りの説明はオフィシャルドキュメントにあります.
https://www.scalactic.org/user_guide/Tolerance
ただ,いちいち+-を使って誤差許容範囲を書くのはめんどくさい.scalaのimplicitを使うとこう書けます.
scala> import org.scalactic.TolerantNumerics import org.scalactic.TolerantNumerics scala> val epsilon = 1e-1 scala> implicit val doubleEq = TolerantNumerics.tolerantDoubleEquality(epsilon) doubleEq: org.scalactic.Equality[Double] = TolerantDoubleEquality(0.1) scala> a === 1.1 res6: Boolean = true
この場合,誤差範囲が0.1より大きくなると等しくなくなります.
scala> a === 1.2 res9: Boolean = false
目的は数値同士の比較ではなく,NDArrayのベクトルなり行列なりを比較することなので,もう少し拡張します.
Equality
Equalityを使って,ベクトル同士をどう比較するかを定義します.通常の比較だとベクトルの各成分を==で比較しますが,それを変更し,ベクトルの各成分をTolerance付きの===で比較するように変更すれば良さそうです.
scala> import org.scalactic._ import org.scalactic._ scala> import TripleEquals._ import TripleEquals._ scala> import Tolerance._ import Tolerance._ scala> import org.scalactic.TolerantNumerics import org.scalactic.TolerantNumerics scala> val epsilon = 1e-1 epsilon: Double = 0.1 scala> implicit val doubleEq = TolerantNumerics.tolerantDoubleEquality(epsilon) doubleEq: org.scalactic.Equality[Double] = TolerantDoubleEquality(0.1) scala> import org.scalactic.Equality import org.scalactic.Equality scala> import org.nd4j.linalg.api.ndarray.INDArray import org.nd4j.linalg.api.ndarray.INDArray scala> implicit val ndarrayEq = | new Equality[INDArray] { | def areEqual(a: INDArray, b: Any): Boolean = | b match { | case p: INDArray => a.shape === p.shape && | (0L until a.shape()(0)).map(f => | a.getDouble(f) === p.getDouble(f)) | .foldLeft(true)((g,h) => g && h) | case _ => false | } | | } ndarrayEq: org.scalactic.Equality[org.nd4j.linalg.api.ndarray.INDArray] = $anon$1@5c5bf478 scala> import org.nd4j.linalg.factory.Nd4j import org.nd4j.linalg.factory.Nd4j scala> val a = Nd4j.create(Array(1.0, 2.0)) log4j:WARN No appenders could be found for logger (org.nd4j.linalg.factory.Nd4jBackend). log4j:WARN Please initialize the log4j system properly. log4j:WARN See http://logging.apache.org/log4j/1.2/faq.html#noconfig for more info. a: org.nd4j.linalg.api.ndarray.INDArray = [ 1.0000, 2.0000] scala> val b = Nd4j.create(Array(1.1, 1.9)) b: org.nd4j.linalg.api.ndarray.INDArray = [ 1.1000, 1.9000] scala> a === b res0: Boolean = true
Equalityについては,オフィシャルドキュメントに説明があります.
https://www.scalactic.org/user_guide/CustomEquality
一応イケたんですが,1次元ベクトルしか対応していないので,行列やテンソルに拡張するにはもう少し改良が必要です.
■
WF-XB700を買った

久しぶりにソニー製のオーディオ製品を買いました.
完全ワイヤレスで,1万円とか2万円の安い値段帯のものを探していました.走る時に使いたかったので,音質やノイズキャンセリングは二の次で,自分の耳にフィットするものを探していました.どの製品を試しても耳からスカッと取れる感じでランニング時には使えないなーという感じだったのですが,この製品だけ,耳にはめてぐるっと回すと,妙にピッタリとハマったので即買いしました.
毎日,走る時に使ったり,通勤など電車に乗る時に使っていても,取れたり落ちたりすることはありません.「クイック充電にも対応しており、10分の充電で60分再生可能」というのも良いです.
なお,以前に買ったソニーのオーディオ製品は,ソニーのマイページによると次のようなものでした.
NW-E040シリーズ | ポータブルオーディオプレーヤー WALKMAN ウォークマン | ソニー
これも軽かったし,本体にUSBオス端子が付いていて,直接パソコンにぶっ刺してファイルのやり取りができるのが便利でした.
NW-M500シリーズ | ポータブルオーディオプレーヤー WALKMAN ウォークマン | ソニー
これはノイズキャンセリングが秀逸で,通勤時に相当お世話になりました.
AirPodsも考えたのですが,やっぱり走ると吹っ飛びそうな感じがしたので止めました.今のところ,WF-XB700がとっても気に入っています.