Spark RAPIDSを試したら凄かった
NVIDIA Spark RAPIDSを試してみた
Apache Sparkファンとしては,Sparkの色々な活用方法を探しています.特に私はIBM PowerでSparkを使っているので,機械学習のためのライブラリを使おうとすると,色々と苦労しています.幸い,IBM Powerは,ギリギリでNVIDIAのサポートを受けています.例えば,CUDAが使えます.
ならばSparkでCUDAを使ってGPUを活用したい!
と思いますよね.
そこでSpark RAPIDS.
GitHub - NVIDIA/spark-rapids: Spark RAPIDS plugin - accelerate Apache Spark with GPUs
RAPIDSは様々なプロジェクトのトップです.
Open GPU Data Science | RAPIDS
今回は,RAPIDSの中のSpark RAPIDSだけ取り上げます.
ローカルモードで試してみる
私はIBM Power8とIBM Power9から構成されるHadoop YARNクラスタでSparkを使っています.ただ,GPUが付いているPower9は一台しか無いので,SparkをYARNモードじゃなくてlocalモードで試してみます.
細かいことはあとで説明するとして,結果を貼り付けてみます.
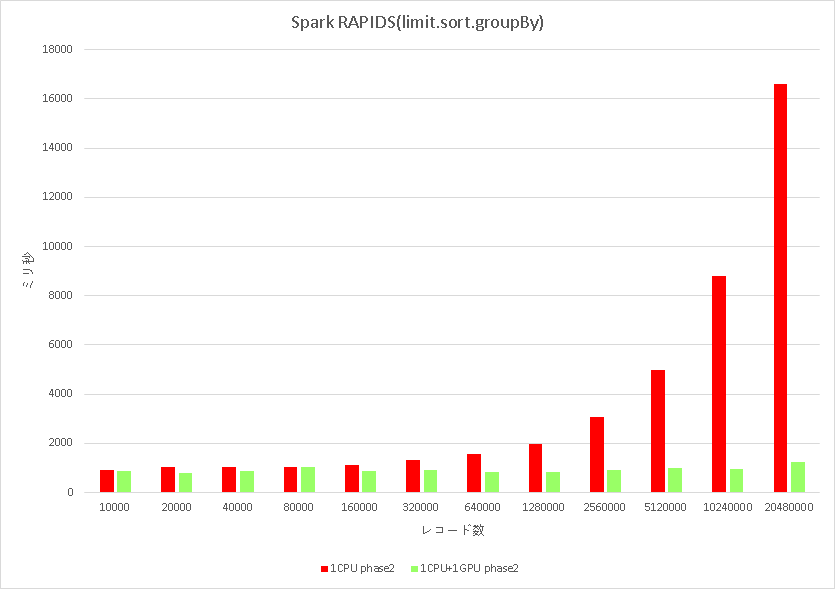
普通に,Hadoopのログファイルを読んで,limitで適当にレコード数を決めて,時間情報でsortして,あるカラムでgroupByするというSpark SQLを実行して,実行時間を計測してみました.
赤はRAPIDSを使わなかった時で,レコード数に比例して処理時間が増えています.緑はRAPIDSを使った時で,レコード数が増えても処理時間が変わりません(!).色々試した結果,GPUのメモリが溢れるまでは定数時間でイケました.
レコード数が20480000,約2000万レコードの時,sparkを--master localでCPUで実行した時は,処理時間が16秒でした.同じjarファイルをspark-submitした場合,1秒でした.16倍の高速化です.
CPUで実行する時と,GPUを使う時は,Sparkのconfigureで切り替えています.GPUを使う場合のConfはこんな感じ.
spark.rapids.shuffle.transport.enabled true spark.rapids.sql.enabled true spark.rapids.sql.explain ALL spark.rapids.sql.concurrentGpuTasks 1 spark.plugins com.nvidia.spark.SQLPlugin spark.rapids.sql.castStringToTimestamp.enabled true
詳細は,順次,報告します!