Scala/SparkのJupterカーネル「Almond」の導入
Jupyter Almondカーネルをインストールする
Spark/Scalaを使うことができるJupyterのカーネルとして,Apache Toreeのメンテナンスをしています.
Apache Toreeは,Spark3対応の開発が進んでいる状況ですが,なにぶん開発がアクティブとは言い難いです.
GitHub - apache/incubator-toree: Mirror of Apache Toree (Incubating)
最後のコミットは昨年8月のようです.
Prepare for next development interaction 0.6.0.dev1 · apache/incubator-toree@fb61d80 · GitHub
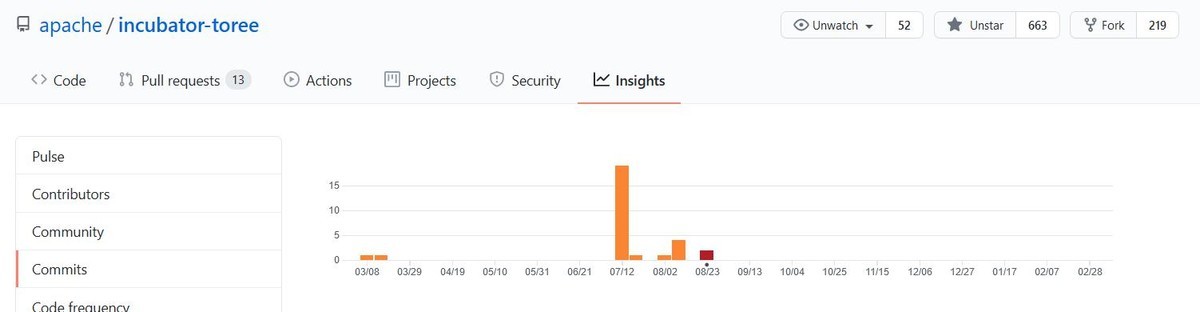
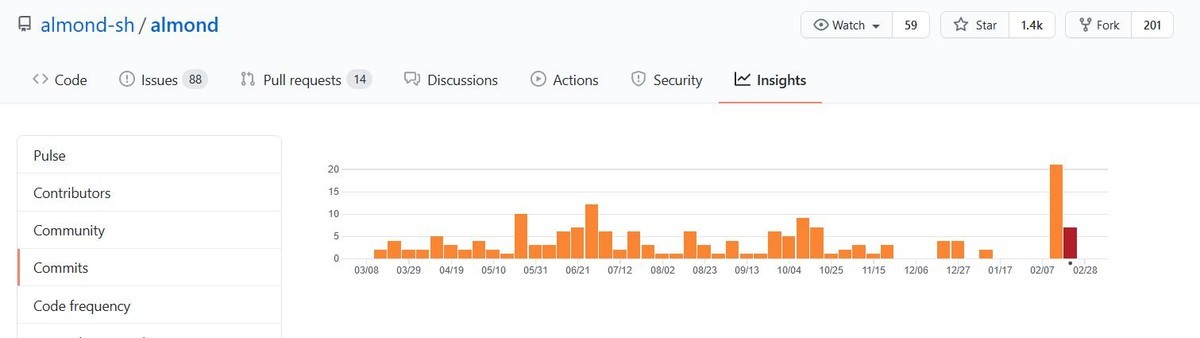
Commit Activityを見ると開発の活発度は一目瞭然です.
そこで,Almondを試しにインストールしてみました.
インストール方法
オフィシャルサイトでは,色々なインストール方法が紹介されています.
Installation · almond
私はこれで行きました.
$ curl -Lo coursier https://git.io/coursier-cli $ chmod +x coursier $ ./coursier -J-Dhttps.proxyHost=[Proxyのアドレス] -J-Dhttps.proxyPort=[Proxyのポート] bootstrap almond:0.11.0 --scala 2.12.9 -o almond $ ./almond --install --name 'Scale(almond)' --id scala_almond
注:Jupyter自体は予めインストールされているとします.
Proxy設定について
proxyが必要な環境だったので,結構ハマりました.
インストールの際は,上記の用にcoursierコマンドに,Java用のProxy設定オプションを加えます.また,Jupyterを立ち上げてカーネルとしてscala_almondを選んでからも,ライブラリインストールのために以下のコマンドをノートブック上で実行します.
System.setProperty("https.proxyHost","Proxyのアドレス") System.setProperty("https.proxyPort", "Proxyのポート")
Sparkを使うためには,以下のようにSparkのライブラリを導入します.
import $ivy.`org.apache.spark::spark-sql:3.1.1`
そういや,ちょうどSpark-3.1.1がリリースされました.
Spark 3.1.1 released | Apache Spark