IntelliJ IDEA Community 2021でgithubと連携したsbt projectを作る
苦労してやり方を探したのですが...
IntelliJ IDEA Community 2021でsbt projectを設定する - なぜか数学者にはワイン好きが多い
その後もライブラリの設定などめんどくさいことが続いて,もっといいやり方を探したというお話.
やりたかったことは,
- 空のgithubプロジェクトがあるので,そこにプロジェクトを登録したい
- プロジェクトはsbtプロジェクトとしたい
- Scala3を使ってみたい
というのをIntelliJを使って,という感じ.
前回はgithubプロジェクトをIntelliJにインポートするということをやってみたのですが,もっと良い方法はありました.
やり方は以下.
Scala3のプロジェクトを作成する
File→New→Projectで,新規プロジェクトを作成します.そしてDottyを選びます.


リモートの管理を選ぶ


IntelliJ IDEA Community 2021でsbt projectを設定する
何度目かのハマりだったので,メモしておきたい.
なんでデフォルトでantプロジェクトになっちゃうんだろう.新規でsbtプロジェクトを作成するのではなく,なんらかのはずみでできてしまったプロジェクトを,あとからsbtプロジェクトにする方法が分からなかったという話.
やろうとしたこと/やってみたこと
- IntelliJ IDEA Community 2021でScalaを書こうと思った
- githubにREADME.mdしか作っていないプロジェクトがあったので,それを利用しようと思った
- IntelliJで,githubのカラプロジェクトをimportする形で新規プロジェクトを作った
- IntelliJのTerminalで,Scala3のテンプレートを作った
sbt new scala/scala3.g8
- IntelliJ上ではsbtプロジェクトだと認識されず,sbt shellも見当たらずsbt ツールウィンドウも出ない
- Build Projectを選んでも,antが走るのみでsbtコマンドは実行されない
- IntelliJをいくら触っても,プロジェクトの設定をantからsbtに変更する設定が見当たらなかったので,最初からsbtプロジェクトとしてIntelliJ上で作成したファイルとの違いを調べてみた
- githubからimportしたプロジェクトは,.idea/sbt.xmlというファイルがあるが,内容がしょぼい
こんな感じでした↓
<?xml version="1.0" encoding="UTF-8"?> <project version="4"> <component name="ScalaSbtSettings"> <option name="customVMPath" /> </component> </project>
- そこで,最初からsbtプロジェクトとして作成したプロジェクトのファイルと,しょぼい内容を適当にマージして.idea/sbt.xmlを上書きした
こんな感じ↓
<?xml version="1.0" encoding="UTF-8"?> <project version="4"> <component name="ScalaSbtSettings"> <option name="customVMPath" /> <option name="linkedExternalProjectsSettings"> <SbtProjectSettings> <option name="externalProjectPath" value="$PROJECT_DIR$" /> <option name="modules"> <set> <option value="$PROJECT_DIR$" /> <option value="$PROJECT_DIR$/project" /> </set> </option> <option name="sbtVersion" value="1.4.9" /> </SbtProjectSettings> </option> </component> </project>
- IntelliJを再起動したら,sbtツールウィンドもsbt shellも出てきた(∩´∀`)∩わーい
sbtツールウィンドウ↓

sbt shell↓

なんでもっと簡単に設定できないんだろう?
NumPyのインストール: /usr/include/xlocale.h:27:16: エラー: ‘struct __locale_struct’ の再定義です
元々はOptunaをインストールしようとしていたのですが,よく分からないエラーでインストールできない.調べているとNumPyのインストールが失敗しているらしいということで,NumPy単独でインストールしてみようとしていました.
$ pip3 install numpy==1.21 (中略) In file included from numpy/core/src/common/numpyos.c:23: /usr/include/xlocale.h:27:16: error: redefinition of ‘struct __locale_struct’
numpyos.cのコンパイルに失敗している.
よく分からないので,ソースからのビルドに挑戦する.
$ git clone https://github.com/numpy/numpy.git $ cd numpy/ $ python3 setup.py build -j 16 install --user (中略) gcc: numpy/core/src/common/numpyos.c In file included from numpy/core/src/common/numpyos.c:23: /usr/include/xlocale.h:27:16: error: redefinition of ‘struct __locale_struct’ 27 | typedef struct __locale_struct
pip経由でインストールしようとした時と同じエラーが出るので,現象は同じ.
よく分からないので検索してみると,同じエラーでチケットが上がっている模様.
xlocale.h definition conflicts with IBM advanced toolchain · Issue #17347 · numpy/numpy · GitHub
実はIBM Power8で作業していたので,このチケットがビンゴ.このチケット自体は現在もクローズされいないが,チケットの内容を読んでいると気付くことは,「/usr/local/bin/gccを使っているのに,なぜ/usr/include/xlocal.hのエラーでコンパイルが失敗する?」ということ.もちろん/usr/local/bin/gccはあとからインストールしたものなので,/usr/bin/gccに依存しているところが無いわけではないが,よく考えたらxlocal.hは新しいgccでは使われていない.
Release/2.26 - glibc wiki
The nonstandard header xlocale.h has been removed in this release.
スタンダードじゃないヘッダファイルxlocale.hは,このリリースで削除された
では,なぜ削除されたはずのxlocale.hがビルドで使われようとしているのか?
それは,エラーを出しているnumpyos.cの中でxlocale.hを読み込もうとしているから.
#ifdef HAVE_STRTOLD_L #include <stdlib.h> #ifdef HAVE_XLOCALE_H /* * the defines from xlocale.h are included in locale.h on some systems; * see gh-8367 */ #include <xlocale.h> #endif #endif
マクロHAVE_XLOCALE_Hが定義されている場合に限り,このコードが実行されて,xlocale.hを読み込もうとする.
従って解決方法としては,マクロHAVE_XLOCALE_Hを定義しない,というのが正しい.この余計なことをするマクロHAVE_XLOCALE_Hは,setup.pyを実行すると作成されるnumpy/core/include/numpy/config.hの中に書かれている.
#define HAVE_XLOCALE_H 1
なので,この行を消してしまうというのが解決法になる.このファイルは
build/src.linux/numpy/core/include/numpy/config.h
みたいな場所にあるはずなので,適当なテキストエディタで該当の行を探し,削除し保存すれば良い.
改めてインストールを試みると,無事成功します.
python3 setup.py build -j 16 install --user (中略) Finished processing dependencies for numpy==1.22.0.dev0+377.gf128be6c6
第83回情報処理学会全国大会の情報保障
気になった情報保障(字幕)について
今回も情報処理学会全国大会に参加したんですが,
情報処理学会 第83回全国大会 - なぜか数学者にはワイン好きが多い
最終日,いつものようにIPSJ-oneに参加しました.
情報処理学会第83回全国大会
IPSJ-ONE
日時:3月20日(土)15:30-18:00
会場:特別会場【セッション概要】情報処理学会には多数の研究会がある一方,それぞれの研究者が異分野で現在注目されている研究を知る機会は少ない.専門家ではない学生や他分野からの参加者にとってはなおさらである.そこで本企画では,多様な研究分野を垣根なく俯瞰するため,若手を中心とする優れた研究者が次々と登壇し,各自の研究を端的に紹介する.専門家のみならず,高校生,学部生,他分野の参加者にも理解しやすい講演を提供する.優れた研究と高いプレゼン力のある研究者を各研究会に推薦頂き,研究の内容などを考慮して登壇者を厳選した.分かりやすいプレゼンと完成度の高い演出を通じて優れた研究者をハイライトしつつ,異分野も含めた交流が研究を更に発展させるような場を目指す.また,マスメディア・ネットメディア等を通じた多数のアウトリーチも予定している.
IPSJ-oneでは毎年字幕生成がやられていて,試みはいいなあと思いつつ精度は悪いなーと思ってました.
リアルタイムに音声認識して文字で提示されていたのですが,ミスが多くてひどい.ところが今年は,IPSJ-one以外の情報保障セッションは参加できなかったので分からないのですが,IPSJ-oneでは,事前に収録したビデオに対し字幕作成したんですかね?講演者が話す前に字幕が出てました.
とてもプレゼンが盛り上がっていた,NTTの石畠さんの講演だとこんな感じ.
どうやって字幕作ったんですかね.メカニズムを公開して欲しい.
まあ,たぶん近く説明してもらえると思うので,楽しみにしています.
Jupyter上で,Scalaで画像データを表示する
ScalaをJupyter上で使うノウハウを蓄積したい
Scalaはコンパイル型の言語ですが,REPLが使えるのでインタプリタ的に開発ができて便利です.
なのでサーバコンソール上でも十分な開発ができるのですが,Jupyterを導入することでさらに便利になります.
Scala/SparkのJupterカーネル「Almond」の導入 - なぜか数学者にはワイン好きが多い
ノートブックとして作業履歴や実行結果を記録できることも便利なのですが,画像データなんかを扱う場合,コンソールだと表示できない画像を表示できるのが便利です.
ところがScalaあるあるで,ドキュメントが少ないのでJupyter-Almond-Scalaで画像データを表示したりする方法がよく分からないです.そこでブログを書いてみるって感じです.
almond上でscalaノートブックを開く
まず,こちらの通りに,ノートブックを開いて頂きたい.
Jupyter labをインストールしてScalaをSparkで使う
情報処理学会 第83回全国大会 - なぜか数学者にはワイン好きが多い
ノートブック上でファイル保存されている画像データを読み込む
画像ファイルを表示するapiは準備されていて,
Image.fromFile("ここに画像ファイルのパスを書く")
これで表示できます.Imageはalmondの内蔵クラスなので,importしたりライブラリを持ってくる必要は無いです.
こんな感じ

もうちょいカッコよく表示するためには,例えばこんなメソッドを定義するのが良いかと思います.
def getImageText(imageFile: String) = s"data:image/png;base64,${Image.fromFile(imageFile).data.get("image/png").get}"
こいつを使うと,画像を並べたり色々できると思います.例えばこんな感じ.
Html(s"<table><tr><td><img src=${getImageText("/tmp/image-2-0-219-80.png")}></td><td><img src=${getImageText("/tmp/image-3-3-226-80.png")}></td></tr></table>")

情報処理学会 第83回全国大会
2021年情報処理学会全国大会
今年も参加しました
情報処理学会第83回全国大会
オンライン開催のため,以前のように現地の写真をレポートすることができないのが残念です.
2017年情報処理学会全国大会。 - なぜか数学者にはワイン好きが多い
情報処理学会第76回全国大会に行ってきた - なぜか数学者にはワイン好きが多い
第75回情報処理学会全国大会 - なぜか数学者にはワイン好きが多い
2012年第74回情報処理学会全国大会出席まとめ - なぜか数学者にはワイン好きが多い
情報処理学会全国大会2011 - なぜか数学者にはワイン好きが多い
第70回情報処理学会全国大会 - なぜか数学者にはワイン好きが多い
初のオンライン開催では,バタバタと決まったこともあり,学生さんの参加者が激減した記憶があります.
情報処理学会第82回全国大会
が,今回は参加者は多かったように思います.
印象的だったのは,オンラインに慣れている何人かの学生さんが,ビデオ映像を入れて上手にプレゼンテーションをアピールした発表をしていることです.Zoom操作・パソコントラブル等もずいぶん減ったような印象でした.
ちょっとだけ負担が増えたことは,情報処理学会ではオンライン開催のトラブルを防ぐため,セッションの座長の他に「座長補佐」というものを置くようになりました.だいたいの人は座長と座長補佐の両方を引き受けることになるため,準備の手間が2倍になった感じです.まあ,仕方がないかなーと思います.
また,オンラインの方が質疑応答参加のハードルが高いのか,質問等が圧倒的に減ったように思います.座長も現場の雰囲気が見えないために時間により質疑応答を打ち切りやすく,時間は比較的守られる反面,全国大会のコミュニケーションを促進するという目的に対してはイマイチのイベントになっているなあという気がしました.
ああ,本当に字ばっかりの記事になった笑
自分の発表の時に,前の職場の同僚が聴講参加しているのを見つけてしまい,超緊張した&もっと面白いネタで発表すれば良かったと後悔したのは秘密です.
# t2sy氏,君だw
Jupyter labをインストールしてScalaをSparkで使う
この間,
注:Jupyter自体は予めインストールされているとします.
と書いたところを,一応丁寧に.
自分の備忘録として.
AWS EC2にインストールする必要が出たので.
EC2にデフォルトではpython2しか入っていなかったので,python3を入れてjupyterをインストールします.
sudo yum install python3-devel pip-3 install --user jupyterlab
jupyterを立ち上げた時にブラウザが立ち上がらないようにするとかパスワードやトークンを不必要にしてセキュリティレベルを落とす(アクセス元制限とか他の方法でセキュリティ設定がされていることとする)とか,設定を変更します.
jupyter lab --generate-config emacs .jupyter/jupyter_lab_config.py c.ExtensionApp.open_browser = False c.ServerApp.token = ''
ここまででjupyter-labを立ち上げると,ランチャーにはデフォルトで登録されているpythonなどが出ます.

ここで,紹介した方法でalmondをインストールします.
Scala/SparkのJupterカーネル「Almond」の導入 - なぜか数学者にはワイン好きが多い
その後,jupyter-labを立ち上げると,ランチャーにscalaが出ます.

Scala(almond)を選んでノートブックを立ち上げたあと,sparkを使うにはライブラリをインポートします.
あと,ドキュメントにあるようにログレベルも変更します.
Spark · almond
import $ivy.`org.apache.spark::spark-sql:3.1.1` import $ivy.`sh.almond::almond-spark:0.11.0` import org.apache.log4j.{Level, Logger} Logger.getLogger("org").setLevel(Level.OFF)
ライブラリのインポートが成功したあとに,sparkセッションのインスタンスを作成します.
import org.apache.spark.sql._ val spark = { NotebookSparkSession.builder() .master("local[*]") .getOrCreate() }
あとは,sparkを使う感じで実行ができます.
import spark.implicits._ val a = Seq(1,2,3).toDF a.show +-----+ |value| +-----+ | 1| | 2| | 3| +-----+
簡単で,素敵ですね(colla風)
Scala/SparkのJupterカーネル「Almond」の導入
Jupyter Almondカーネルをインストールする
Spark/Scalaを使うことができるJupyterのカーネルとして,Apache Toreeのメンテナンスをしています.
Apache Toreeは,Spark3対応の開発が進んでいる状況ですが,なにぶん開発がアクティブとは言い難いです.
GitHub - apache/incubator-toree: Mirror of Apache Toree (Incubating)
最後のコミットは昨年8月のようです.
Prepare for next development interaction 0.6.0.dev1 · apache/incubator-toree@fb61d80 · GitHub
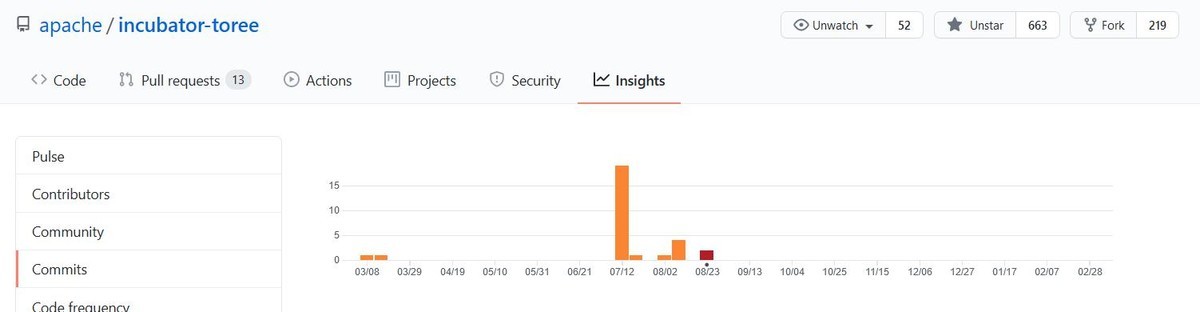
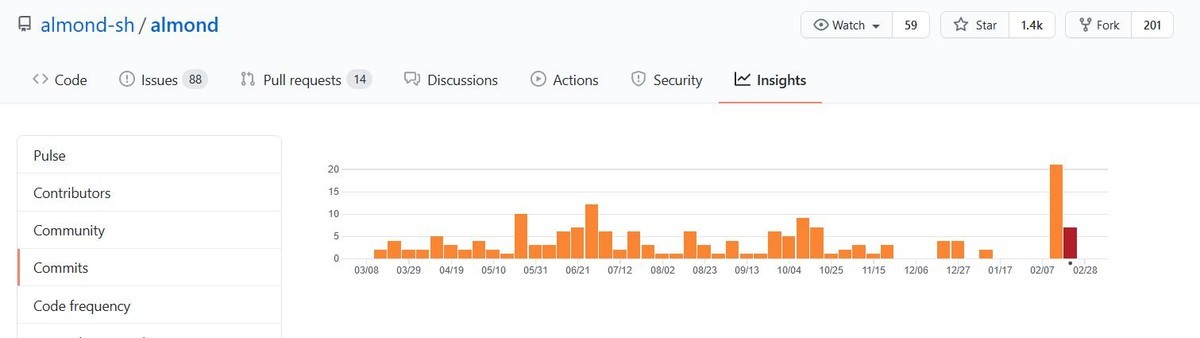
Commit Activityを見ると開発の活発度は一目瞭然です.
そこで,Almondを試しにインストールしてみました.
インストール方法
オフィシャルサイトでは,色々なインストール方法が紹介されています.
Installation · almond
私はこれで行きました.
$ curl -Lo coursier https://git.io/coursier-cli $ chmod +x coursier $ ./coursier -J-Dhttps.proxyHost=[Proxyのアドレス] -J-Dhttps.proxyPort=[Proxyのポート] bootstrap almond:0.11.0 --scala 2.12.9 -o almond $ ./almond --install --name 'Scale(almond)' --id scala_almond
注:Jupyter自体は予めインストールされているとします.
Proxy設定について
proxyが必要な環境だったので,結構ハマりました.
インストールの際は,上記の用にcoursierコマンドに,Java用のProxy設定オプションを加えます.また,Jupyterを立ち上げてカーネルとしてscala_almondを選んでからも,ライブラリインストールのために以下のコマンドをノートブック上で実行します.
System.setProperty("https.proxyHost","Proxyのアドレス") System.setProperty("https.proxyPort", "Proxyのポート")
Sparkを使うためには,以下のようにSparkのライブラリを導入します.
import $ivy.`org.apache.spark::spark-sql:3.1.1`
そういや,ちょうどSpark-3.1.1がリリースされました.
Spark 3.1.1 released | Apache Spark